Deep Neural Network(2)
18 Oct 2019 | DNN loss function gradient decent back propagationDeep neural network
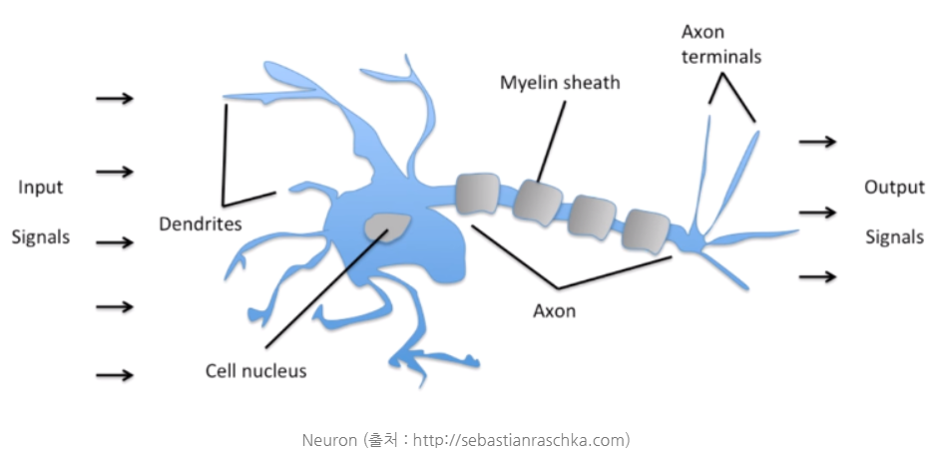
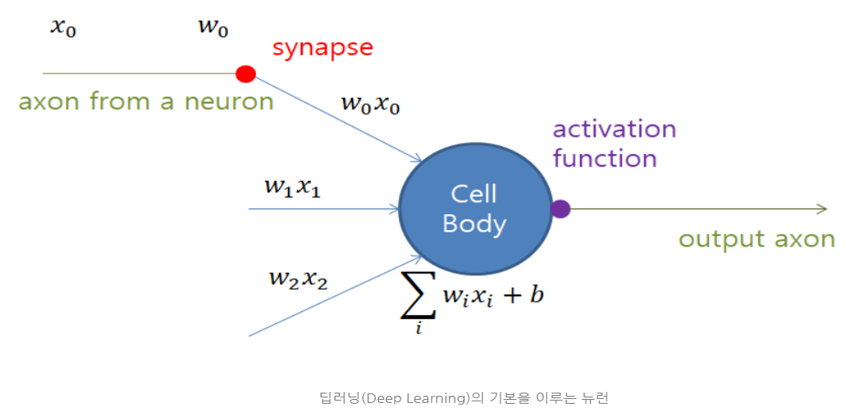
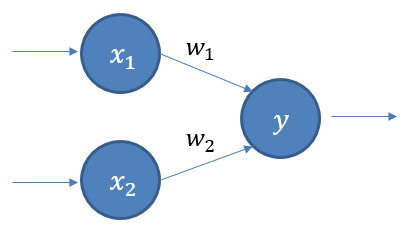
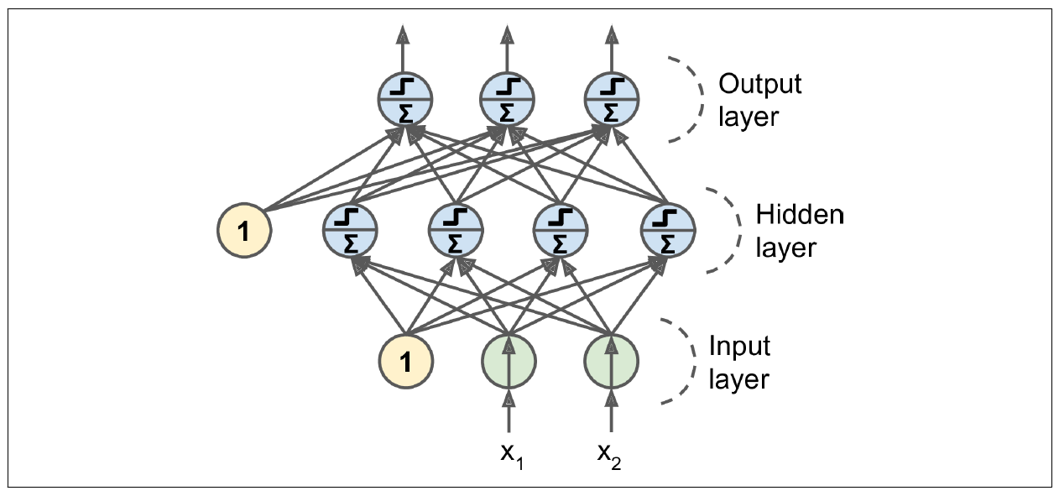
- ANN에서 Input layer와 Output layer를 제외한 중간 layer들을 모두 hidden layer라고 하며, hidden layer의 개수가 2개 이상이면 DNN이라 한다.
- Output layer를 제외하고는 모두 bias 뉴런을 포함하며 다음 층과 연결 되어있다.
손실 함수(loss or cost function)
- 네트워크(모델) 구조가 정해지면 모델이 학습을 진행하기 위해서는 손실 함수를 정의 해야 한다.
- 손실함수는 네트워크의 출력과 우리가 원하는 값의 차이를 의미하며, 주로 아래 두 함수들로 정의된다.
- 손실함수의 종류
- 평균 제곱 오차(Mean Squared Error, MSE) : 주로 회귀(regression)에 사용
$$ Error\quad =\quad \frac { 1 }{ n } \sum _{ k }^{ n }{ { ({ y }_{ k }-{ t }_{ k }) }^{ 2 } } $$ - 교차 엔트로피 오차(Cross Entropy Error, CEE) : 주로 분류(classification)에 사용
$$ Error\quad =\quad \frac { 1 }{ n } \sum _{ k }^{ n }{ { { t }_{ k } }\log { { y }_{ k } } } $$
경사 하강법(Gradient Descent)
- 손실 함수를 최소로 하는 매개변수를 찾기 위한 알고리즘으로 경사 하강법(이하 GD)을 사용한다.
- Neural Network에서 매개변수는 각 layer의 weight와 biase이다.
- 알고리즘
- 매겨변수를 초기화한다.
- 손실 함수를 미분하여 기울기를 계산한다.
- 기울기에 learning rate를 곱하여 매개변수를 변경한다.
$$ { W }_{ n }:={ W }_{ n-1 }-\alpha \frac { \partial }{ \partial W } cost(W) $$ - 위 과정을 허용오차(tolerance)까지 반복한다.
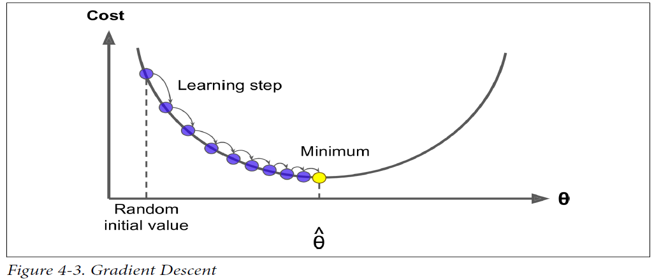
- GD는 일반적으로 많이 사용되며 Batch GD, Stochastic GD 등의 응용이 있다.
- 주의
- 정의된 손실 함수는 미분 가능 해야 한다.
- gradient가 너무 작으면 학습 속도가 느려진다.
- 반대로 gradient가 너무 커지면 발산하여 학습이 정상적으로 이루어지지 않는다.
- 이를 위해 learning rate 설정하고 학습을 진행해야 한다.
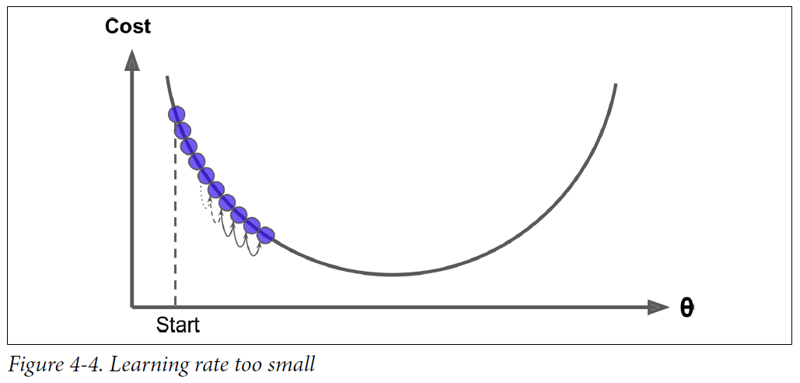
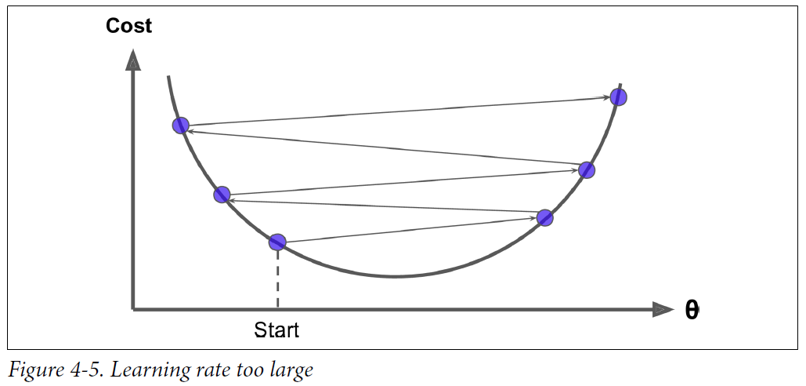
- 즉, 머신러닝에서 학습이란 손실함수를 최소화하는 모델 파라미터를 찾는 과정 이라고 할 수있다.
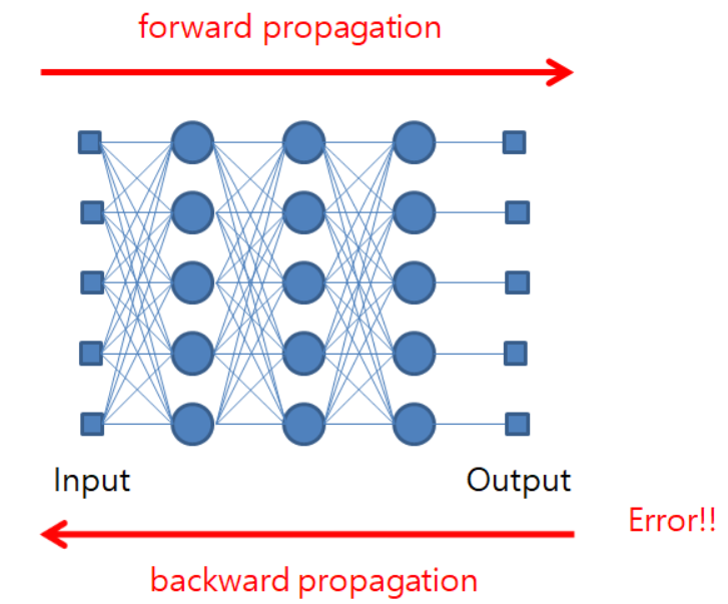
역전파(Back-propagation)
- 앞서 보다시피 딥러닝은 다양한 네크워트 구조를 가질 수 있다.
- 그렇다면, GD으로 구한 gradient를 각 weight와 bias에 어떻게 적용 해야할까?
- Back-propagation은 Neural Network에서의 gradient decent를 적용하기 위해 gradient를 계산하는 알고리즘이다.
- 알고리즘
- 매개변수를 초기화한다.
- 입력 데이터를 매개변수와 계산하여 각 층의 뉴런마다 출력을 얻는다. (forward propagation)
- 출력 데이터와 정답 사이의 오차를 계산한다.
- 역방향으로 각 layer을 거치면서 각 연결(매개변수)이 오차에 기여한 정도(gradient)를 측정한다. (back-propagation)
- 오차가 감소하도록 매개변수를 조금씩 조정한다. (gradient decent)
- 위 과정을 허용오차(tolerance)까지 반복한다.
- 한 노드에 대한 back-propagation
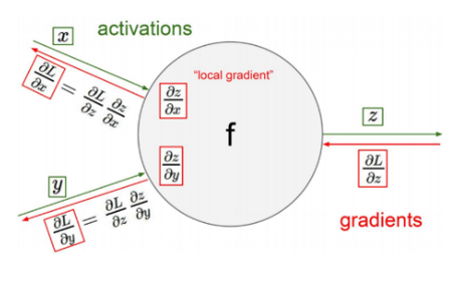
- \(x,y\) : 해당 노드의 input
- \(f\) : 해당 노드의 연산자
- \(z\) : 해당 노드의 output
- \(L\) : 계산되어진 손실 값
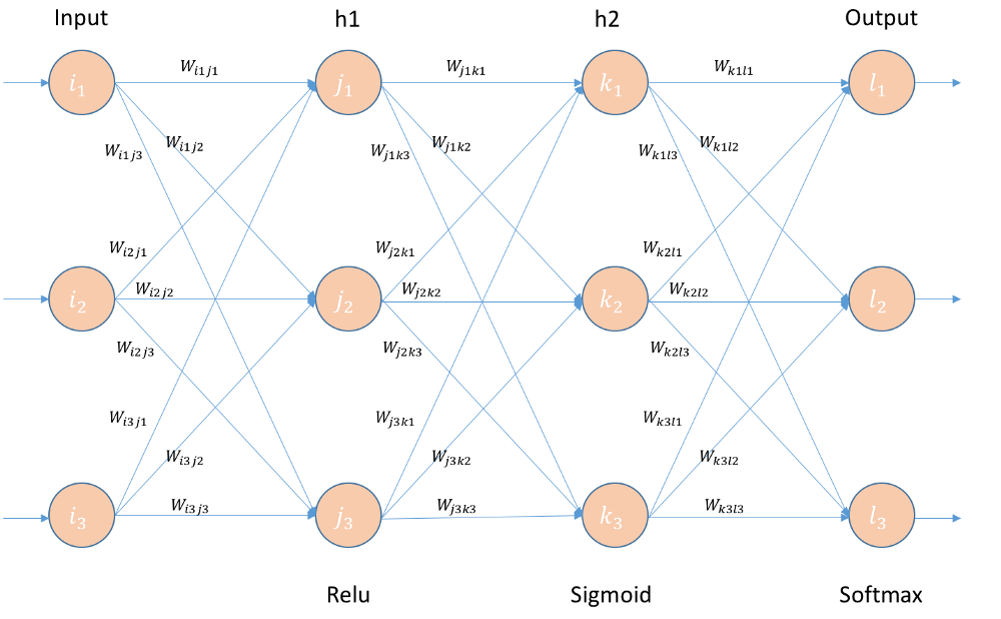
- 예를 들어, 3 layer DNN이 있다고 하자. 구조는 다음과 같다.
- 다음 그림은 hidden layer2와 output layer 사이의 back-propagation을 보여준다.
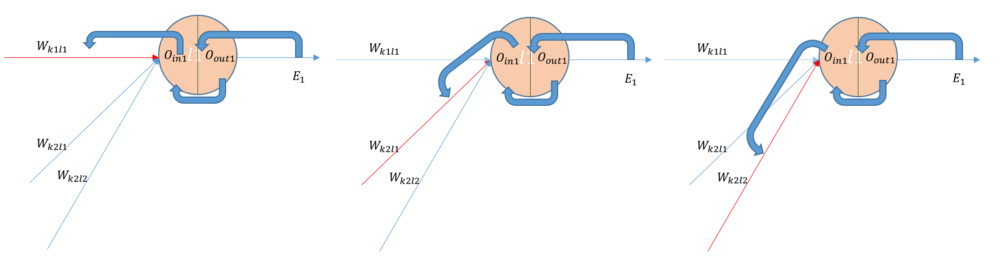
- forward-propagation을 통해 계산된 \(loss({E}_{1})\)를 미분하여 해당 그레디언트를 각각 connection의 weight로 넘겨준다.
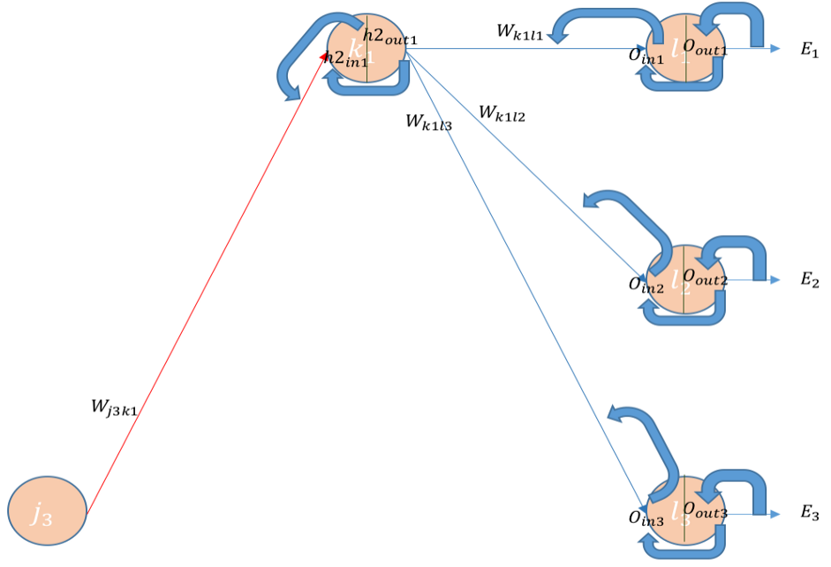
- 전달된 그레디언트를 그 다음 layer로 넘겨주며 해당 전파는 input layer까지 진행된다.
- gradient가 input layer까지 전달된 후 gradient descent를 적용하여 매개변수를 변경한다.
- 앞선 과정에서 각 layer별로 gradient를 계산해야 하기 때문에 활성함수는 미분 가능 해야한다.
- 계단 함수는 사용할 수 없으며, 대신 시그모이드 함수를 사용 할 수 있다.
- 그 외에도 다양한 활성 함수들을 사용할 수 있다.
여기까지만 해서 학습이 잘 되면 얼마나 좋을까…
우리 딥러닝 학습의 여정은 순탄치 않았는데…
[다음 편 예고] gradient가 자꾸 지멋대로 집을 나가거나 열폭해요
참고 자료
- http://it.plusblog.co.kr/221243889886
- https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
- https://medium.com/@14prakash/back-propagation-is-very-simple-who-made-it-complicated-97b794c97e5c