Youtube 추천 시스템 리뷰
29 Oct 2019 | 추천_시스템 recommendation youtube1. 소개
- 유튜브 추천에 3가지 핵심 고려 사항
- scale
- 대부분의 추천 알고리즘은 많은 양의 컨텐츠을 감당할 수 없었다.
- 고도의 분산 알고리즘과 효과적인 서비스 시스템이 필수적이다.
- freshness
- 신규 컨텐츠 와 잘 구성된 컨텐츠 사이의 균형을 이해 해야한다.
- exploitation / exploration trade-off를 고려해야 한다.
- 참고 : https://conceptually.org/concepts/explore-or-exploit
- noise
- 사용자 행위 기록은 관찰할 수 없는 희소성(sparsity)와 다양성(variety) 때문에 예측하기 어렵다.
- 사용자 만족을 얻기 거의 어렵고 대신 오염된 피드백을 모델링 하게 된다.
- 메타 메타데이터는 잘 구조화 되어 있지 않다.
- 추천 알고리즘은 학습 데이터의 개별적 특성에 견고해야 한다.
- 구현
- Tensorflow로 구현됨
- 학습 데이터
- 약 10억개의 파라미터
- 약 수천억개의 샘플
- scale
2. 시스템 개요
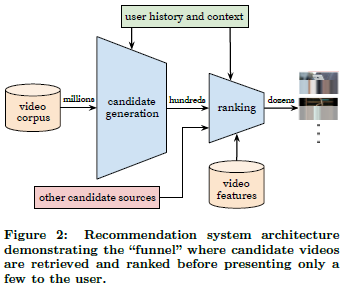
- 후보 생성 모델과 랭킹 모델이 분리
- 후보 모델은 사용자의 행위 기록과 큰 모음에서 후보 비디오 집합 생성
- 랭킹 모델은 후보 집합에 순위를 부여
- 후보 모델은 협업 필터링을 통해서만 개인화를 제공하며, recall을 중요시 해야 한다.
- 컨텐츠 내용 뿐만 아니라 사용자의 이용내역과 맥락을 감안해야 한다.
- 분석 방향성
- offline에서는 precision/recall/ranking loss등을 최적화하며,
- A/B 테스트에서는 시청 시간/클릭률을 개선 했다.
- 사용자 사이의 유사도는 비디오 시청 아이디, 검색어 토큰, 인구 통계와 같이 거친 feature으로 표현된다.
3. 후보 생성
- ranking loss를 이용한 Matrix factorisation이 일반적이다.
- 인공신경망을 사용하여 MF를 대체하였으며, 과거 사용자의 비디오 내역을 사용하였다.
3.1 분류를 통한 추천
- 문제 정의
- 다량의 컨텐츠에 대한 엄청나게 많은 클래스가 존재
- 사용자 \(U\), 맥락 \(C\) 가 주어진 때, 특정 시간 \(t\) 에 비디오 \({W}_{t}\)를 볼 확룔을 구함
- \[P({ w }_{ t }=i|U,C)\quad =\quad \frac { { e }^{ { v }_{ i }u } }{ \sum _{ j\in V }^{ }{ { e }^{ { v }_{ j }u } } }\]
- \({ v }_{ j }\) : 각각 후보 영상 임베딩
- \(u\) : 사용자 & 맥락 임베딩
- 명시적인 사용자가 누른 ‘좋아요’ 같은 정보는 사용하지 않고, 암시적인 ‘비디오를 끝까지 시청 했는가’와 같은 데이터를 사용함
- 다량의 클래스 분류 문제에 대한 효율적인 구현
- in offline
- negative class를 샘플링 (i.e., skip-gram negative sampling)
- loss function으로는 각 class (비디오)마다 (binary) cross-entropy를 사용
- 대략 수천개정도의 negative sample 이용
- 기존 방식보다 100배 이상 빨라짐
- hierarchical softmax는 정확성이 떨어져 사용하지 않음
- in 실 서비스
- 사용자에게 추천을 N개의 비디오를 제공
- 이전에 진행된 [24]처럼 hashing을 활용
- 최종적으로는 (위의 식처럼) dot-product space에서 가장 가까운 컨텐츠 (nearest neighbour)를 찾는 과정.
- A/B test 결과 nearest neighbour 알고리즘간에 추천성능 차이는 없음
- in offline
3.2 후보 생성 모델 구조
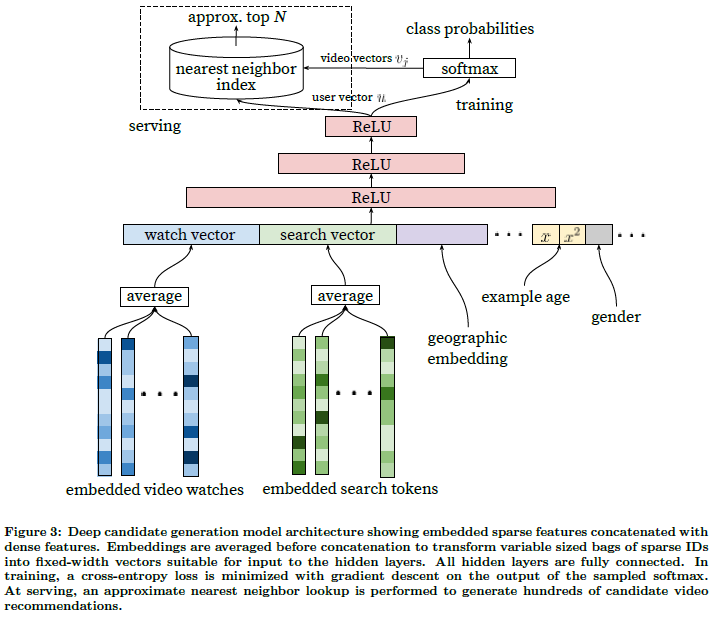
- 사용자의 시청 내역을 embedding vector로 변환
- 여러 영상들의 embedding vector에 대한 평균을 계산하여 input으로 활용(watch vector)
- FC + ReLU 사용, layer 추가시 ReLU 추가
3.3 타입이 다른 데이터
- 연속형, 범주형 변수를 임베딩하여 활용.(matrix factorization의 일반화)
- 지리 정보, 성별을 활용
- 영상의 나이 고려
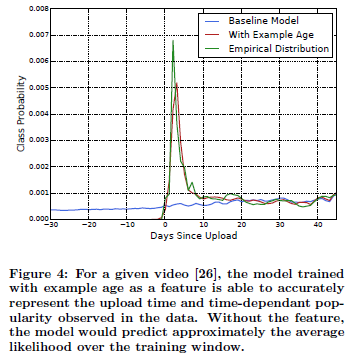
- freshness를 반영하기 위함.
- 영상의 나이를 고려해주면(빨강) 사용자의 실제 컨텐츠 소비 패턴(초록)과 유사 해진다.
- 학습 단계에서는 값을 넣어주고 실제 서비스 단계에서는 모두 0으로 처리 했다.(비디오 인기도 분포가 불안정한기 때문에)
3.4 label과 context 선택
- 추천은 surrogate problem을 수반하고 있다.
- 높은 정확도가 효과적인 영화 추천을 만든다는 가정이 전형적인 예이다. (exploitation » exploration)
- exploitation & exploration trade off를 고려 해야 한다.
- 해결 방안
- 다른 소스를 활용 : 유튜브 추천에 지속적으로 영향을 받기 때문에
- 사용자별 감상 횟수를 제한 : 하나의 컨텐츠를 많이 보는 사람들의 영향을 감소시키기 위해
- 추천 결과나 검색 결과를 즉시 활용하지 않음
- 검색 키워드는 일부러 순서를 날린 bag-of-tokens을 이용
- 그렇지않으면 방금 검색한 내용이 계속 메인 페이지에 노출됨
- 비 대칭적인 유튜브 영상 패턴
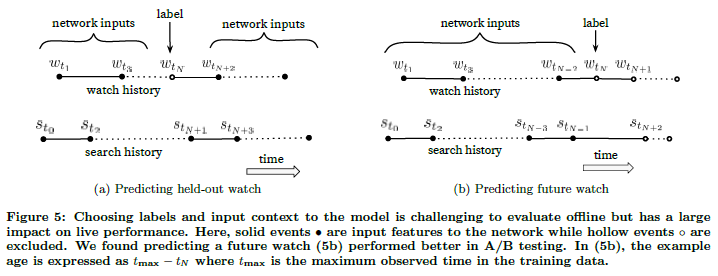
- 비대칭적인 co-occurrence (or co-watch)
- 즉, 전 영상에 따라 다음에 어떤 영상을 볼지 영향이 크다.
- 에피소드의 경우 일반적으로 순서가 정해져 있다.
- 대부분의 카테고리에서 가장 유명한 영상에서 마이너한 영상으로 가는 경향이 있다.
- 대부분의 협업 필터링 모델은 임의적으로 기간의 라벨과 맥락, 사용자 기록에서 임의적
- 대조적으로 비대칭적 feature을 고려하여, 과거의 데이터만 사용해야함 (5-b)
3.5 feature과 depth에 대한 실험
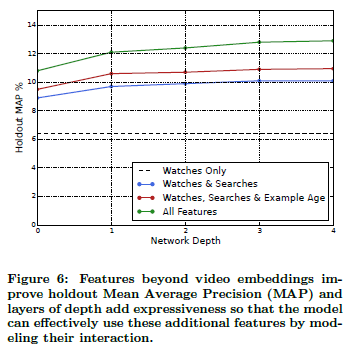
- MAP(Mean Average Precision) 측정
- baseline : 감상 내역만 이용
- 파랑색: 감상내역 + 검색
- 빨강색: 감상내역 + 검색 + 영상의 나이
- 초록색: 전부 다
- layer 기준
- 깊이 0 : 256 노드 softmax
- 깊이 1 : 256 노드 ReLU
- 깊이 2 : 512 노드 ReLU → 256 ReLU
- 깊이 3 : 1024 노드 ReLU → 512 ReLU → 256 ReLU
- 깊이 4 : 2048 노드 ReLU → 1024 노드 ReLU → 512 ReLU → 256 ReLU
- 실험은 영상 100만개, 검색어 100만개를 256차원의 embedding으로 변환. bag_size는 최근 50개 영상/검색
- depth 깊어질수록 성능 좋아짐
4. 랭킹
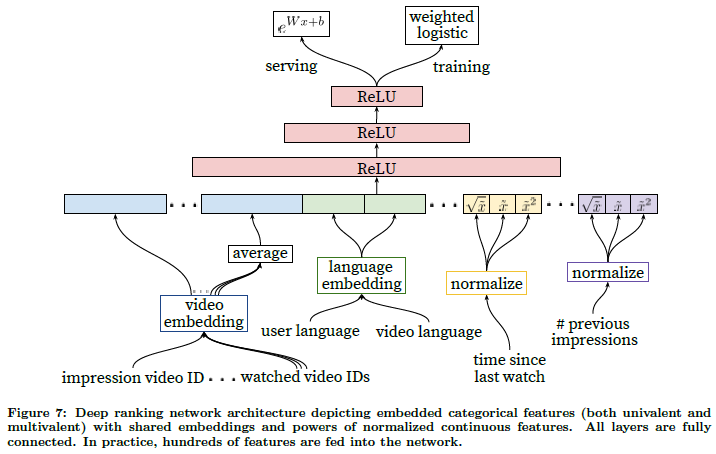
- 더 많은 특징 활용
- A/B 테스트를 통해 지속적으로 업데이트
- 평가 지표는 추천 횟수 대비 평균 시청 시간
4.1 feature representaion
feature engineering
- 사용자 행위에 일시적인 순서와 영상에 대한 인상과 이런 행동이 어떻게 점수를 매길 수 있는지를 고민함
- 사용자는 이 채널에서 얼마나 많은 영상을 봤는가?
- 사용자는 이 주제를 언제 마지막에 봤는가?
- 위 항목은 서로 다른 항목에 대해 잘 일반화 되어 있어 효과적
- 후보 생성 모델에서 정보를 전달 받는게 중요함
- 후보를 지명 했던 정보원은?
- 지명에 대한 영향이 정도는?
- 추천에 대한 인상도 고려 해야함
- 추천 되었지만 지속적으로 시청하지 않는다면 순위를 낮추어야 한다.
범주형 feature 임베딩
- 후보 생성과 유사하게 spare한 범주형 특징을 dense한 표현으로 임베딩
- 각 ID 공간은 훈련 전에 만들어진 look-up 테이블이다.
- 상위 Top-N만 남기고 다 0으로 초기화
- 모델에 입력 전에 평균을 적용
- 인상 받은 영상, 사용자가 마지막으로 본 비디오 ID, 추천되어진 비디오 ID 등 사용 가능
- 임베딩 공유는 일반화, 학습 속도 향상과 메모리 요구량 감소를 위해 중요
연속형 feature 정규화
- 딥러닝은 입력 데이터의 pre-processing에 매우 민감
- 값들을 누적 분포를 통해 [0, 1] 범위로 scaling
- 값들의 비선형성 학습을 쉽게 하기 위해 제곱, 제곱근을 다 feed
4.2 Modelling expected watch time
- 시청 시간을 예측 하기 위해 weighted logistic regression을 적용
- weighted logistic regression - 감상한 영상을 감상 시간으로 가중치 적용
- 가중치 공산은 부정적 인상 대비 총 시청 시간을 기준으로 함
- 긍정적인 인상이 적다고 가정하면, 학습된 확률은 대략 \(E[T](1+P)\)
- \(P\) : 클릭률
- \(E[T]\) : 예상되는 시청 시간
4.3 hidden layer에 대한 실험
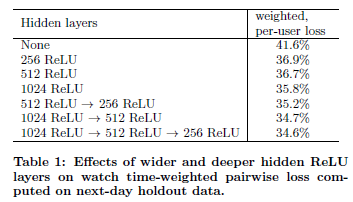
- 더 넓고 깊은 신경망이 더 잘 작동
- 실 서비스의 응답시간을 고려하여 네트워크 구성 필요
5. 결론
- deep learning을 이용하여 Matrix factorization 개선
- 전체 시스템을 디자인하는건 거의 과학이 아니라 예술임.
- “영상의 나이”는 feature로써 잘 활용되어 짐
- 랭킹은 전통적인 ML 문제이지만 deep learning은 다양한 형태의 데이터를 잘 표현하는 representation을 학습 가능
- 특히 사용자의 과거 행동 패턴을 잘 설명하는 feature가 중요
- 시청 시간에 대한 weighted logistic regression을 적용한 것이 click-through rate을 적용한 것보다 좋은 성능을 보임
[24] J. Weston, A. Makadia, and H. Yee. Label partitioning for sublinear ranking. In S. Dasgupta and D. Mcallester, editors, Proceedings of the 30th International Conference on Machine Learning (ICML-13), volume 28, pages 181–189. JMLR Workshop and Conference Proceedings, May 2013.